Building SoTA Convolution Neural Networks for Image Recognition
CNN
Resnet
MNIST
IMAGENETTE
Code
Published
May 10, 2022
Overview
In this blog post, we will explore the architecture of Convolution Neural Networks (CNN) and how they have been used to achieve state-of-the-art performance in image recognition tasks. We will also discuss some of the key components of CNNs, such as convolution layers, pooling layers, and activation functions. Finally, we will look at one of the most popular CNN architectures: ResNet.
Here is the environment that we applied to train the CNN model(s):
Code
import osimport subprocessimport torchdef run_cmd(cmd):try: out = subprocess.check_output(cmd, stderr=subprocess.STDOUT, shell=True, text=True)return out.strip()exceptExceptionas e:returnf"(error running `{cmd}`: {e})"def print_cuda_info():print("torch.cuda.is_available():", torch.cuda.is_available())print("torch.version.cuda:", torch.version.cuda)print("cudnn version:", torch.backends.cudnn.version() if torch.backends.cudnn.is_available() else"<cudnn not available>")if torch.cuda.is_available():print("torch.cuda.device_count():", torch.cuda.device_count())for i inrange(torch.cuda.device_count()):try: name = torch.cuda.get_device_name(i)exceptException: name ="<unknown>"print(f" GPU {i}: {name}")try: cur = torch.cuda.current_device()print("torch.cuda.current_device():", cur)exceptException:passelse:print("No CUDA GPUs detected by torch.")# print("\nnvidia-smi output (if available):")print(run_cmd("nvidia-smi --query-gpu=index,name,memory.total,utilization.gpu --format=csv,noheader,nounits"))print_cuda_info()
In the context of computer vision, feature engineering is the process of using domain knowledge to extract distinctive attributes from images that can be used to improve the performance of machine learning algorithms. For instance, in image classification tasks, the number 7 is characterized by a horizontal edge near the top, and a diagonal line that goes down to the right. These features can be used to distinguish the number 7 from other digits.
It turns out that finding the edges in an image is a crucial step in computer vision tasks. To achieve this, we can use a technique called convolution. Convolution is a mathematical operation that takes two inputs: an image and a filter (also known as a kernel). The filter is a small matrix that is used to scan the image and extract features. For example, the following filter can be used to detect horizontal edges in an image.
Convolution Layer
A convolution layer applies a set of filters (i.e., kernel) to the input image to extract features. Each filter/kernel is a small matrix that is used to scan the image and extract features. The output of a convolution layer is a set of feature maps, which are the result of applying each filter to the input image.
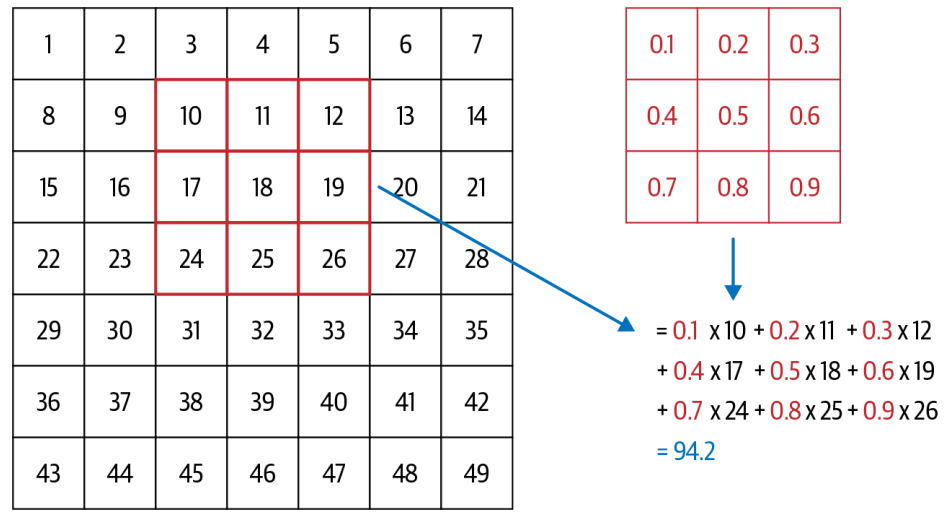
Figure 1: An example of kernel
As illustrated in Figure Figure 1, a 3x3 matrix kernel is applied to the input image, which is 7x7 grid. The kernel is applied to each pixel in the image, and the output is a new pixel value that is calculated by taking the dot product of the kernel and the corresponding pixels in the image. This process is repeated for each pixel in the image, resulting in a new feature map.
Let’s take another look at how convolution works in practice. We will use the im3 image, which is a 28x28 grayscale image of the digit 3 from the MNIST dataset. We will apply a 3x3 kernel to the image to extract features.
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
2
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
3
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
4
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
5
0
0
0
12
99
91
142
155
246
182
155
155
155
155
131
52
0
0
0
0
0
0
0
0
0
0
0
0
6
0
0
0
138
254
254
254
254
254
254
254
254
254
254
254
252
210
122
33
0
0
0
0
0
0
0
0
0
7
0
0
0
220
254
254
254
235
189
189
189
189
150
189
205
254
254
254
75
0
0
0
0
0
0
0
0
0
8
0
0
0
35
74
35
35
25
0
0
0
0
0
0
13
224
254
254
153
0
0
0
0
0
0
0
0
0
9
0
0
0
0
0
0
0
0
0
0
0
0
0
0
90
254
254
247
53
0
0
0
0
0
0
0
0
0
Let’s define a kernel that detects horizontal edges in the image. The kernel is a 3x3 matrix with values that are designed to highlight horizontal edges.
This kernel will detect horizontal edges in the image by emphasizing the differences between the pixel values in the top and bottom rows of the kernel, we can also change the kernel to have the row of 1s at the top and -1s at the bottom, we can detect horizontal edges that go from dark to light, putting 1s and -1s in columns versus rows give us filters that detect vertical edges.
With convolution arithmetic, the kernel is applied to each pixel in the image, resulting in a new feature map that the dimensions are smaller than the original image. This is because the kernel cannot be applied to the pixels at the edges of the image. To address this issue, we can use two techniques: strides and padding.
Strides refer to the number of pixels by which we move the kernel across the image. By default, the stride is set to 1, meaning we move the kernel one pixel at a time. However, we can increase the stride to reduce the size of the output feature map. For example, if we set the stride to 2, the kernel will move two pixels at a time, resulting in a smaller output feature map.
Padding involves adding extra pixels around the edges of the image before applying the kernel. This allows us to preserve the spatial dimensions of the input image in the output feature map. There are different types of padding, such as zero-padding (adding zeros) and reflection padding (adding a mirror image of the border pixels).
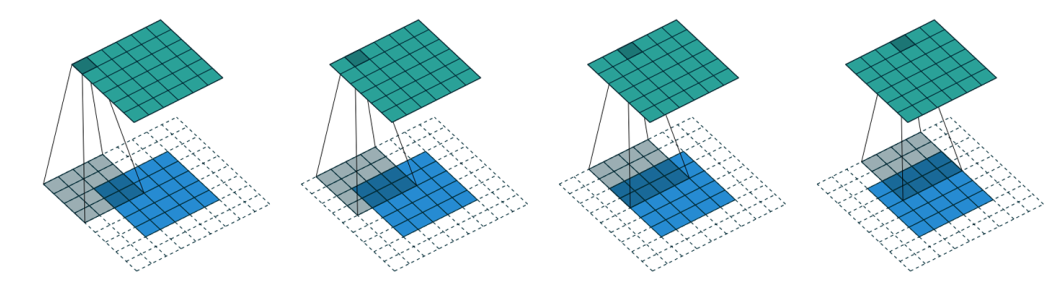
Figure 2: An example of padding with stride of 2
As illustrated in Figure 2, a 5x5 input image is padded with a 2-pixel border of zeros, resulting in a 7x7 padded image. A 4x4 kernel is then applied to the padded image with a stride of 1, resulting in a 5x5 output feature map.
In general, if we add a kernel of size \(ks \times ks\) (\(ks\) is an odd number) to an input image of size \(n \times n\), the neccessary padding \(p\) to preserve the spatial dimensions of the input image in the output feature map is given by: \[
p = ks//2
\] When \(ks\) is even, we can use asymmetric padding, for example, if \(ks=4\), we can use \(p=(ks//2, ks//2-1)\).
Furthermore, if we apply the kernel with a stride of \(s\), the output feature map will have dimensions: \[
\text{output size} = (n + 2p - ks)//(s) + 1
\]
Create a Convolution Layer with PyTorch
We can create a convolution layer using PyTorch’s nn.Conv2d class. The nn.Conv2d class takes several parameters, including the number of input channels, the number of output channels, the kernel size, the stride, and the padding.
In this example, we create a convolution layer with 1 input channel (grayscale image), 30 output channels (feature maps), a kernel size of 3x3, a stride of 1, and padding of 1. We also apply the ReLU activation function after the first convolution layer. One interesting property to note here is that we do not need to specify the input size when creating the convolution layer because a convolution is applied over each pixel automatically.
When creating cnn as above, we see that the output shape is the same as the input shape, which is (28, 28) (This is because we have used padding to preserve the spatial dimensions of the input image in the output feature map). It is not interesting for classification task since we need only single output activation per input image.
To deal with this, we can use several stride-2 convolution layers to reduce the spatial dimensions of the input image in the output feature map. For example, we can use two stride-2 convolution layers to reduce the spatial dimensions of the input image from (28, 28) to (7, 7), (4x4), (2x2) and then 1.
Code
def conv(ni, nf, ks=3, act=True): res = nn.Conv2d(ni, nf, stride=2, kernel_size=ks, padding=ks//2)if act: res = nn.Sequential(res, nn.ReLU()) return res
Then, we create a simple cnn which consists of several convolution layers with stride of 2, kernel size of 3 to reduce the spatial dimensions of the input image in the output feature map. We also flatten the output feature map before passing it to the final classification layer.:
To test our simple_cnn, we can train a classification model from a batch of images from the MNIST dataset to see how effective of the feature extraction it is. To do this, we build a Learner from simple_cnn and dataset dls as follows:
Sequential (Input shape: 64 x 1 x 28 x 28)
============================================================================
Layer (type) Output Shape Param # Trainable
============================================================================
64 x 4 x 14 x 14
Conv2d 40 True
ReLU
____________________________________________________________________________
64 x 8 x 7 x 7
Conv2d 296 True
ReLU
____________________________________________________________________________
64 x 16 x 4 x 4
Conv2d 1168 True
ReLU
____________________________________________________________________________
64 x 32 x 2 x 2
Conv2d 4640 True
ReLU
____________________________________________________________________________
64 x 2 x 1 x 1
Conv2d 578 True
____________________________________________________________________________
64 x 2
Flatten
____________________________________________________________________________
Total params: 6,722
Total trainable params: 6,722
Total non-trainable params: 0
Optimizer used: <function Adam at 0x7f80db0d0fe0>
Loss function: <function cross_entropy at 0x7f818edfc860>
Callbacks:
- TrainEvalCallback
- CastToTensor
- Recorder
- ProgressCallback
As we can see, the output of the final Conv2D layer is 64x2x1x1, that’s why we need to flatten it before passing it to the final classification layer.
Afterwards, let’s train the model with low learning rate and 2 epochs using fit_one_cycle function.
Code
learn.fit_one_cycle(2, 1e-2)
epoch
train_loss
valid_loss
accuracy
time
0
0.063304
0.043649
0.987733
00:03
1
0.016500
0.028673
0.990677
00:03
Impressive, we are able to achieve over 98% accuracy on the classification task with MNIST dataset using simple CNN architecture (built from scratch).
Improving Training Stability
So far, we have created a simple 2D CNN for image classification task over the MNIST dataset and achieved around 98% accuracy. In this section, we will talk about several techniques that we can use to improve the training stability and performance of our model. To make it more interesting, we will train a CNN model to recognize 10 digits from the MNIST dataset and apply several techniques to improve its performance.
Use more activation functions
One simple tweak that we can apply to improve recognition accuracy is to use more activation functions in our CNN, as we need more filters to learn more complex patterns in 10-digit MNIST samples. To achieve this, we add one more activation function after each convolution layer in our simple_cnn architecture. As a result, the number of activations ends up being doubled.
However, adding more activation functions can lead to a subtle (training) problem. Specifically, when we apply 3x3-pixel kernel to the first convolution layer with 4 output filters, we embed information from 9 input pixels into 4 output pixels. While doubling the number of activation functions, we have the computation of 8 output pixels from 9 input pixels. It makes neural networks more difficult to learn the features while mapping from 9 input pixels to 8 output pixels than from 9 input pixels to 4 output pixels.
To deal with this issue, we can increase the kernel size from 3 to 5, which allows us to embed information from 25 input pixels into 8 output pixels. This makes it easier for the neural network to learn the features while mapping from 25 input pixels to 8 output pixels.
To train the model more quickly, we can set learning rate to 0.06 and use ActivationStats callback to monitor the activation statistics during training.
/home/ldinh/perso/perso/lib64/python3.11/site-packages/fastai/callback/core.py:71: UserWarning: You are shadowing an attribute (modules) that exists in the learner. Use `self.learn.modules` to avoid this
warn(f"You are shadowing an attribute ({name}) that exists in the learner. Use `self.learn.{name}` to avoid this")
epoch
train_loss
valid_loss
accuracy
time
0
2.308293
2.303273
0.113500
00:44
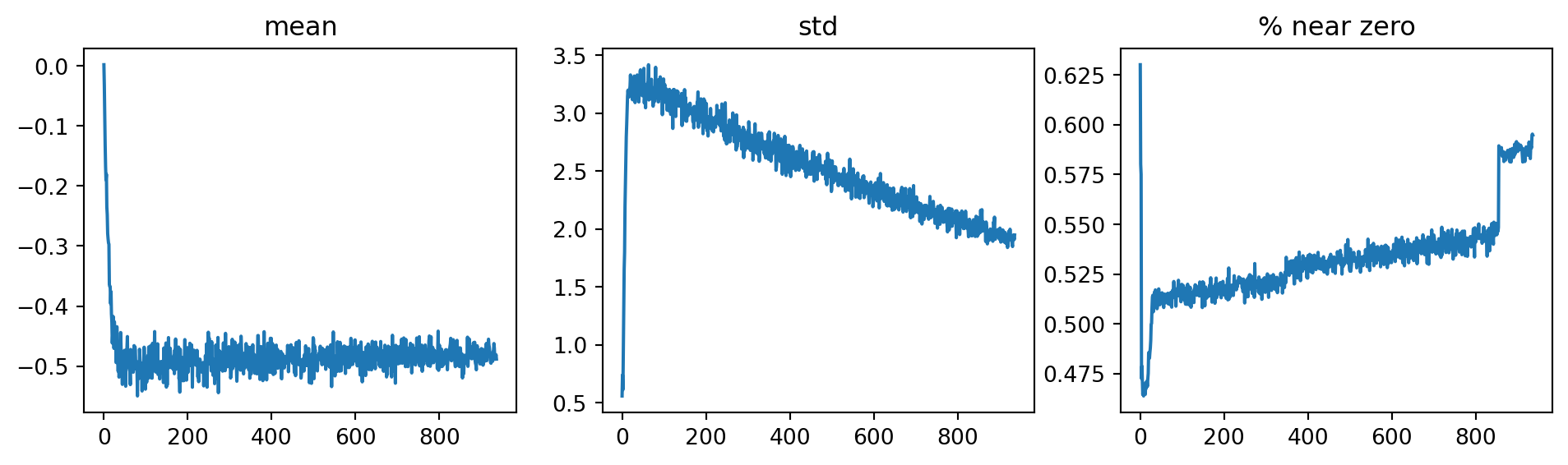
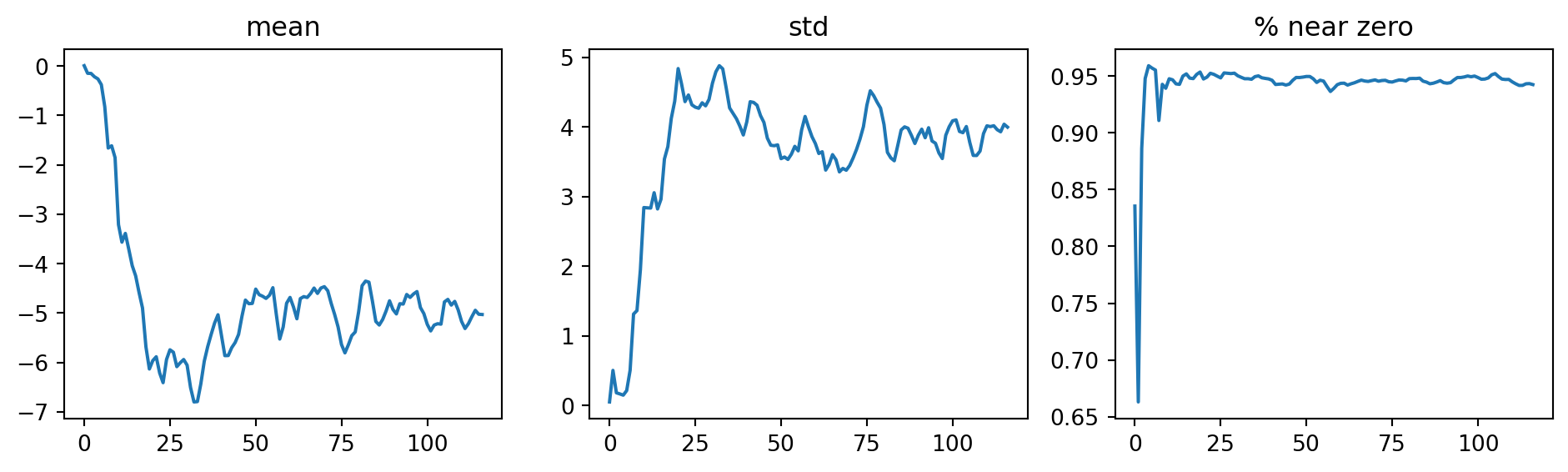
Surprisingly, the model is not trained at all, the accuracy is just around 10% (random guess). To findout what went wrong, we can plot the activation statistics of the first/penultimate convolution layers using ActivationStats callback. It shows that the activations of the first convolution layer are all zeros, and it carries over the next layer, meaning that the model is not learning anything.
Code
from fastai.callback.hook import*# learn.recorder.plot_loss()learn.activation_stats.plot_layer_stats(0)learn.activation_stats.plot_layer_stats(-2)
To fix this issue, we can try several techniques to improve the training stability of our model. ### Increase Batch Size To make training more stable, we can try to increase the batch size, because larger batch sizes prodive more accurate estimates of the gradients, which can help to reduce the noise in the training process. On the downside, larger batch sizes require more memory and less batches per epochs, which bring less opportunities for the model to update its weights, and also it is subject to hardware capabilities.
Code
dls = get_dls(bs=512)learn = fit()
epoch
train_loss
valid_loss
accuracy
time
0
0.355030
0.219721
0.929200
00:17
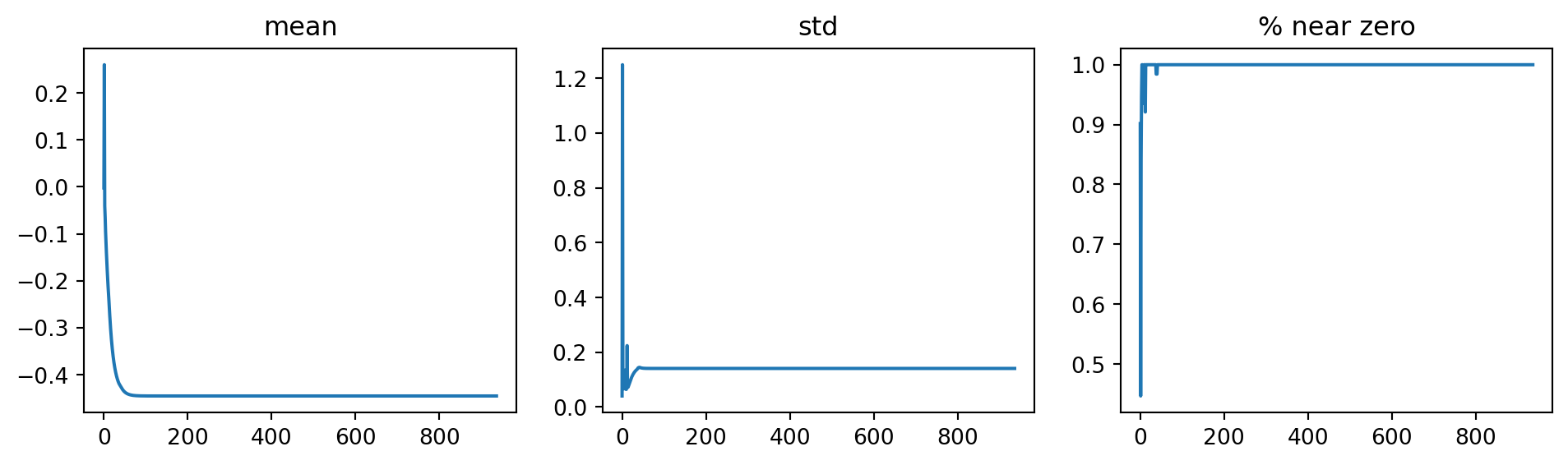
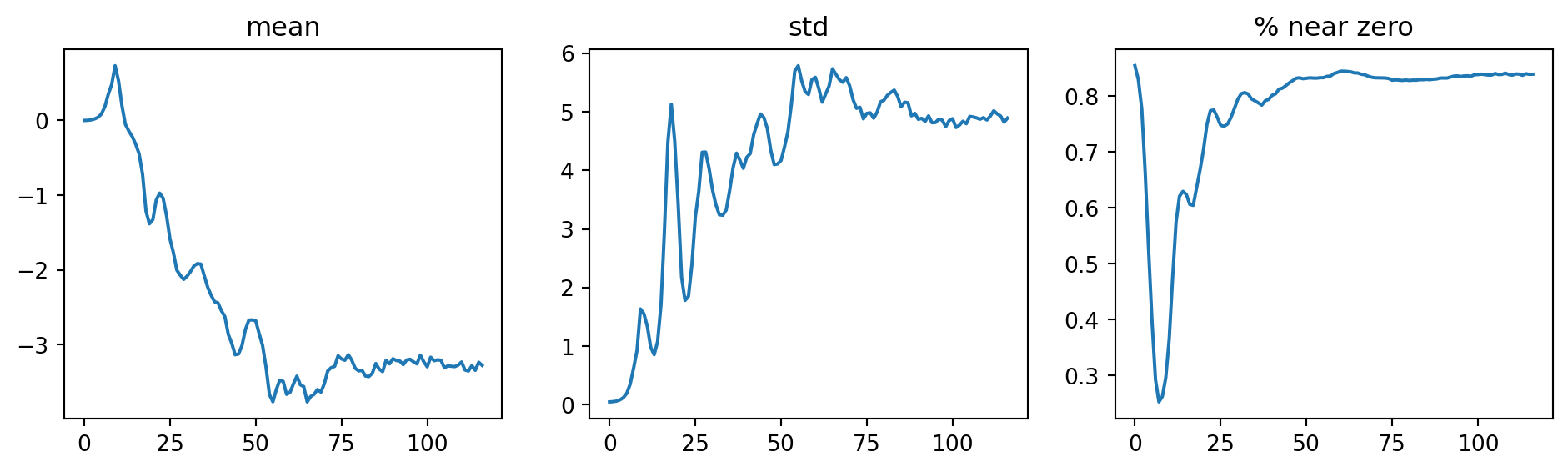
Still, most of the activations are zeros, and the model is not learning anything when we change the batch size to 512 instead of 64.
Learning Rate Finder
It is not favorable that we start training with a high learning rate for a bad initialization of weights. Also, we do not want to end training with a high learning rate either, because it can cause the model to overshoot the optimal weights.
One way to deal with this issue has been proposed by Leslie Smith in his paper Cyclical Learning Rates for Training Neural Networks (Smith, 2017)2. The idea is to use a learning rate that varies cyclically between a lower and upper bound during training. This allows the model to:
Explore different regions of the loss landscape and can help to avoid getting stuck in local minima (higher training rate helps to skip over small local minima).
Improve generalization. Based on the fact that the training model with high learning rate tends to have diverging loss. If it is trained with that high learning rate for a while and it can find a good loss, it will find an area that generalizes well. Thus, a good strategy is to start with a low learning rate, where the loss does not diverge, and then allow optimizer to find smoother areas of parameters by going to higher learning rates. When the smoother areas are found, we can bring the learning rate down again to refine the weights. (i.e. MomentumSGDA Disciplined Approach to Neural Network Hyper-Parameters: Part 1– LEARNING RATE, BATCH SIZE, MOMENTUM, AND WEIGHT DECAY (Smith, 2017)3)
It is implemeted in fastai library as fit_one_cycle function.
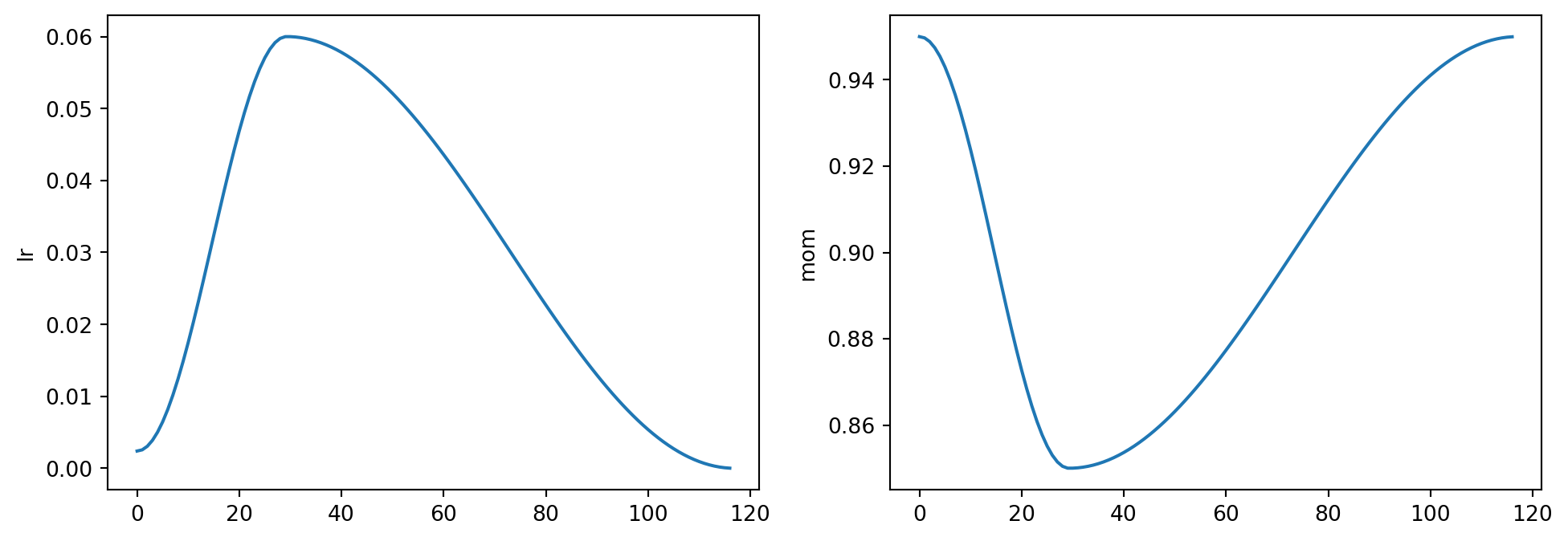
We can view the learning rate schedule and momentum during training by plotting the learning rate using recorder.plot_sched function.
Code
learn.recorder.plot_sched()
For fit_one_cycle function, there are several parameters that we can tune to improve the training stability and performance of our model, such as lr_max,pct_start, div_factor, and final_div_factor. For more details, see the fastai documentation.
To see what is happening to the activations of the penultimate convolution layer, we can plot the activation statistics again. Now, the percentage of dead activations (all zeros) is significantly reduced, and the model is finally learning.
As we paid attention to the activation statistics during training, near-zero activations appear ar the beginning of training and gradually decreases as the training progresses. It suggests that the model training is not smooth because of the cylical learning rate going up and down during the cycle.
To solve this problem, we can use batch normalization technique.
“Training Deep Neural Networks is complicated by the fact that the distribution of each layer’s inputs changes during training, as the parameters of the previous layers change. This slows down the training by requiring lower learning rates and careful parameter initialization, and makes it notoriously hard to train models with saturating nonlinearities.”
To address this issue, they proposed a technique called batch normalization.
“Making normalization a part of the model architecture and performing the normalization for each training mini-batch. Batch Normalization allows us to use much higher learning rates and be less careful about initialization.”
Batch normalization normalizes** the activations of each layer by averaging the means and standard deviations of the activations of a layer use those to normalize the activations. To further deal with situation when we need activation is high to make accurate prediction, they also introduced two learnable parameters per activation (i.e., \(\gamma\) and \(\beta\)), which are used to scale and shift the normalized activations. After normalization, the activations get a vector \(y\), and a batch normalization layer computes the output as follows: \(\gamma*y + \beta\)
By doing so, our activations can have any mean and standard deviation, which are independent from the previous layer.
Figure 3: Batch Normalization
To add batch normalization to our simple_cnn, we can use nn.BatchNorm2d class from PyTorch. We can add a batch normalization layer after each convolution layer in our simple_cnn architecture as follows:
As a result, the accuracy is improved and the model is able to achieve around 98.6% accuracy on the MNIST dataset. Compared to the previous results, we observe that the model tends to generalize better with batch normalization. One possible reason is that batch normalization adds some noise to the activations during training, which can force the model learning more robust to these variations.
As some paper claimed that we should train with more epochs and larger learning rate when using batch normalization, we can try to train the model with 5 epochs and learning rate of 0.1.
epoch
train_loss
valid_loss
accuracy
time
0
0.182030
0.113917
0.968100
00:16
1
0.079044
0.136564
0.960200
00:14
2
0.052621
0.059461
0.981900
00:22
3
0.033798
0.034959
0.988700
00:14
4
0.016711
0.023476
0.992500
00:13
Great, at this point, the model is able to achieve around 99.2% accuracy on the digit recognition task on MNIST dataset, which is a significant improvement compared to the previous results.
Residual Networks (ResNet)
In the digit recognition task performed in MNIST dataset, we need to apply several convolution layers to reduce the spatial dimensions of the input image, which is 28x28 pixels, to a single output activation (using Flatten()).
What would happen if we have a larger input image, for example, 128x128 or 224x224 pixels (Imagenette or ImageNet datasets)? We would need to apply more convolution layers to reduce the spatial dimensions of the input image to a single output activation. However, as we add more convolution layers, the model becomes more difficult to train. This is because the gradients become smaller as they are propagated back through the layers, which can lead to the problem of vanishing gradients.
To address this issue, we can think of flattening the final convolution layer so that we can handle the grid size other than 1x1. For example, if the final convolution layer has a grid size of 2x2, we can flatten it to a vector of size 4 and then pass it to the final classification layer. However, this approach has several drawbacks: (1) it does not work with images of different sizes, (2) it requires more hardware resources as the number of activations fed to the final classification layer increases. This problem can be solved using fully connected networks to take the average of the activations across convolutional grid (it is implemented in AdaptiveAvgPool2d in PyTorch).
In the above get_model function, we create a CNN model with several convolution layers to reduce the spatial dimensions of the input image to a single output activation. We also use AdaptiveAvgPool2d to take the average of the activations across convolutional grid before passing it to the final classification layer.
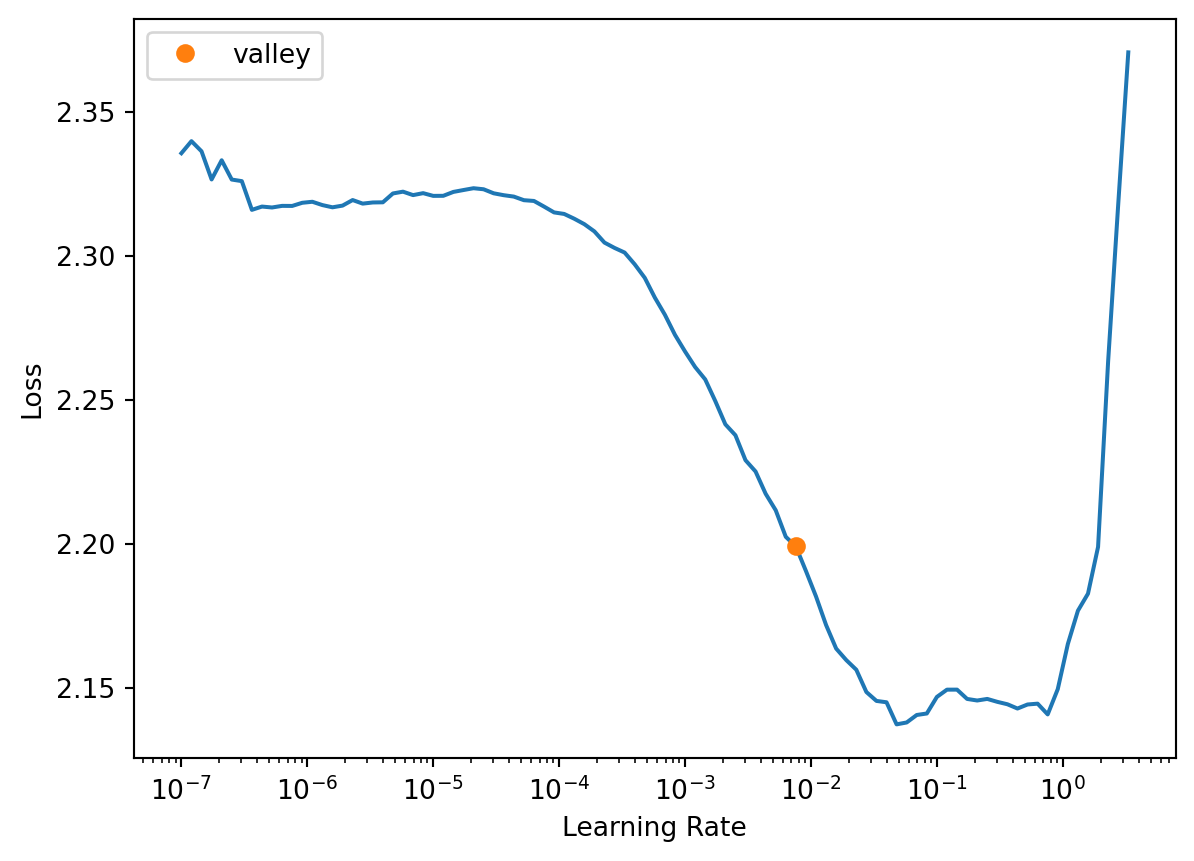
Prior to training the model, we can use learning rate finder to find a good learning rate to start with. It appears that a learning rate of around 3e-3 is a good choice to start with.
It’s a good start, when the model is able to achieve around 70% accuracy on the Imagenette dataset after 5 epochs of training. Let’s try to stack more convolution layers to see if we can improve the accuracy further.
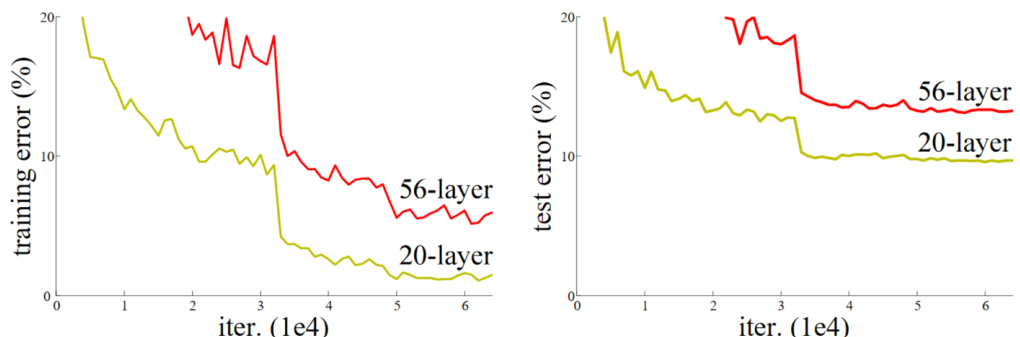
As we can see, we can improve the accuracy of the model by stacking few more convolution layers. However, as we add more convolution layers, the performance of the model starts to degrade. To work around this issue, we can use Residual Networks (ResNet) architecture, which was proposed by Kaiming He et al. in their paper Deep Residual Learning for Image Recognition (He, 2015)5. As illustrated in the paper, adding more layers does not necessarily lead to better performance.
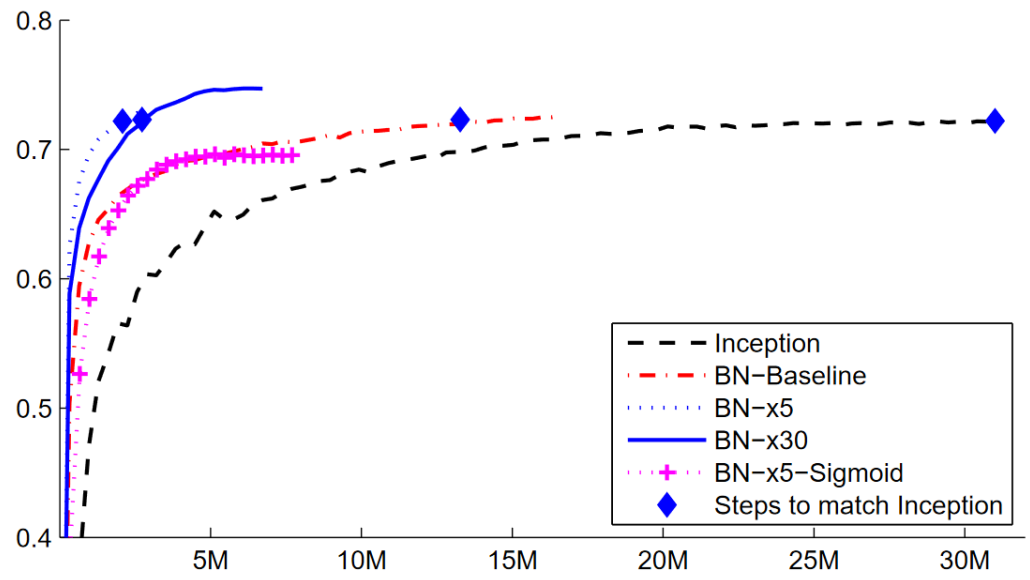
“Unexpectedly, such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher training error, as [previously reported] and thoroughly verified by our experiments.”
Figure 4: Training error w.r.t different layer depth from He et al. paper
Skip Connections in Residual Networks (ResNet)
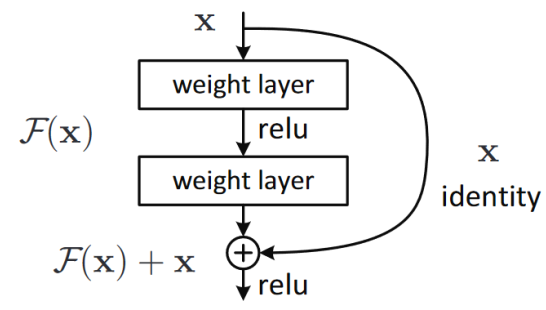
The main idea behind ResNet is to use skip connections to allow the gradients to flow directly through the network, bypassing one or more layers as illustrated in Figure 5.
Figure 5: An illustration of ResNet block
ImportantKey idea
The key idea of ResNet is to learn a residual mapping. Specifically, as the outcome of a given layer is \(x\) and a ResNet block returns \(y = x + block(x)\), instead of trying to predict the original mapping \(block(x)\), which is harder to learn, the network learns the residual mapping, which minimizes the error between \(x\) and \(y\). It enables deeper networks to be trained effectively.
The code block below shows how to implement a ResNet block in PyTorch. We use ConvLayer from fastai library to create the convolution layers in the ResNet block. The first convolution layer has a ReLU activation function, while the second convolution layer uses batch normalization with zero initialization (NormType.BatchZero) to ensure that the initial state of the block is an identity mapping.
ImportantIdentity Mapping
By setting the weights of the second convolution layer’s last batch normalization layer to zero, we ensure that the block output is initially equal to its input, i.e., \(y = x + block(x) \approx x + 0 = x\). By doing so, we take the advantage of adding more layers without degrading the performance of the model (i.e., when deeper network does not bring any advantage, the network can set \(y \approx x\) and does not yield any degradation).
Now, lets create a deeper CNN model using ResNet blocks (twice deeper). We will use the same architecture as before, but we will replace the convolution layers with ResNet blocks.
Coming from “Bags of Tricks for Image Classification with Convolutional Neural Networks” (He, 2019)6, the authors proposed several techniques to improve the performance of ResNet architecture, including tweaking ResNet-50 architecture and Mixup.
Then, we can create a state-of-the-art ResNet model with the following tweaks:
Use stem to enhance computational efficiency
Use Bottleneck Layer in ResNet block to reduce the computational cost and time significantly
Train with larger images (e.g., 224x224 pixels) and more epochs (e.g., 25 epochs)
Use Mixup technique (data augmentation) to further improve the performance of the model.
Stem
The difference compared to our previous ResNet architecture is that they used the stem of the network in the first layer, which consists of few convolution layers followed by a max pooling layer. The stem is considered instead of ResNet block because the vast majority of computatation is in the first few layers of the network, and using a stem can reduce the computational cost and time.
There are four ResNet blocks with 64, 128, 256, and 512 output filters, respectively. Each group starts with a stride-2 block, exept the first group, which is after the MaxPooing layer (stem).
Code
def _resnet_stem(*sizes):return [ConvLayer(sizes[i], sizes[i+1], stride=2if i==0else1) for i inrange(len(sizes)-1)] + [nn.MaxPool2d(3, stride=2, padding=1)]
Code
class ResNet(nn.Sequential):def__init__(self, n_out, layers, expansion=1): stem = _resnet_stem(3, 32, 32, 64)self.block_size = [64, 64, 128, 256, 512]for i inrange(1,5):self.block_size[i] *= expansion blocks = [self._make_layer(*o) for o inenumerate(layers)]super().__init__(*stem, *blocks, nn.AdaptiveAvgPool2d(1), Flatten(), nn.Linear(self.block_size[-1], n_out))def _make_layer(self, i, n_layers): stride =1if i==0else2 ch_in, ch_out =self.block_size[i:i+2]return nn.Sequential(*[ResBlock(ch_in if l==0else ch_out, ch_out, stride if l==0else1) for l inrange(n_layers)])
Another inmprovement we can apply is Bottleneck Layer. Instead of using two 3x3 convolution layers in the ResNet block, we can use a 1x1 convolution layer to reduce the number of filters, followed by a 3x3 convolution layer, and then another 1x1 convolution layer to increase the number of filters back. This reduces the computational cost and time significantly.
We can also create ResNet-50 architecture with 4 groups, of which the sizes are [3,4,6,3] and expansion factor of 4 (we need to start with 4 times fewer channels and end up 4 times more channels).
Training with Larger Images and More Epochs
To really show the benefit of training deeper networks with bottleneck layers (i.e., higher parameters), we should consider more epochs of training (e.g., 20 epochs) And lastly, we can perform ResNet-50 in a dataset with larger images (e.g., 224x224 pixels) to see how well it performs. In this case, we can try with resizing Imagenette_320 dataset with 320x320 pixel images to 224-pixel image dataset.
epoch
train_loss
valid_loss
accuracy
time
0
1.568573
1.411239
0.536815
27:20
1
1.316752
1.420792
0.515159
33:21
2
1.203135
1.260643
0.597197
37:54
3
1.082399
1.235167
0.622420
38:14
4
0.991768
2.533253
0.436178
35:30
5
0.876081
2.736581
0.483567
34:21
6
0.808190
1.086010
0.671592
37:06
7
0.725415
0.993561
0.710573
36:43
8
0.654518
1.118184
0.663694
36:25
9
0.608239
1.103723
0.704459
36:35
10
0.561338
0.896198
0.704968
36:38
11
0.523825
0.853090
0.732739
36:31
12
0.479717
0.696026
0.788790
36:06
13
0.421387
0.640591
0.795414
36:50
14
0.376504
0.877977
0.742930
35:55
15
0.342628
0.582160
0.828025
35:22
16
0.295201
0.486333
0.846879
37:05
17
0.255468
0.397606
0.881019
36:10
18
0.221189
0.427752
0.877197
37:12
19
0.201000
0.365489
0.893248
37:40
20
0.169965
0.362851
0.891210
36:58
21
0.148934
0.327434
0.901656
36:52
22
0.126788
0.326252
0.901911
36:15
23
0.120078
0.325421
0.900382
37:28
24
0.113371
0.326366
0.900127
35:41
The results that we have achieved is great with ResNet-50 model built from scratch (around 86% accuracy on Imagenette dataset with 224x224 pixel images after 25 epochs of training).
Mixup Technique
Finally, we can add Mixup technique to further improve the performance of our model. Mixup is a data augmentation technique that creates new training samples by mixing two random samples from the training set. This can help to improve the generalization of the model and reduce overfitting. It is implemented in fastai library as MixUp callback.
epoch
train_loss
valid_loss
accuracy
time
0
1.100851
0.393920
0.879745
00:48
1
0.963170
0.402768
0.882293
00:46
2
0.899312
0.402251
0.884586
00:47
3
0.866416
0.405769
0.883567
00:47
4
0.850734
0.443996
0.869299
00:46
5
0.846682
0.400968
0.885350
00:46
6
0.851042
0.460827
0.868025
00:47
7
0.853078
0.537936
0.830573
00:47
8
0.853621
0.425499
0.878217
00:46
9
0.855851
0.509069
0.840000
00:48
10
0.858964
0.729920
0.774267
00:47
11
0.866117
0.629298
0.810701
00:47
12
0.865057
0.580092
0.815032
00:47
13
0.880143
0.746360
0.761019
00:46
14
0.876794
0.661403
0.797197
00:47
15
0.877983
0.861207
0.737580
00:47
16
0.870464
0.520097
0.843567
00:47
17
0.869036
0.525145
0.849172
00:46
18
0.859176
0.579815
0.823694
00:46
19
0.842798
0.699460
0.778089
00:47
20
0.836196
0.769553
0.758217
00:46
21
0.835654
0.623200
0.809936
00:47
22
0.831520
0.537588
0.828535
00:47
23
0.823739
0.526208
0.841783
00:47
24
0.798818
0.410245
0.872102
00:46
25
0.794637
0.672540
0.811720
00:46
26
0.768548
0.620026
0.820637
00:46
27
0.773810
0.490456
0.859873
00:47
28
0.751875
0.564618
0.830318
00:48
29
0.768581
0.398642
0.884331
00:47
30
0.749160
0.416314
0.879745
00:47
31
0.734804
0.564898
0.832611
00:48
32
0.730062
0.417930
0.886369
00:47
33
0.732346
0.453399
0.864968
00:47
34
0.726520
0.431738
0.873121
00:46
35
0.722340
0.371893
0.903439
00:45
36
0.700923
0.447503
0.870318
00:45
37
0.692455
0.405109
0.884331
00:46
38
0.689181
0.367990
0.889682
00:46
39
0.684220
0.390246
0.891720
00:46
40
0.689944
0.408053
0.882038
00:45
41
0.681683
0.325703
0.907771
00:45
42
0.668944
0.380991
0.890191
00:46
43
0.659009
0.359641
0.904968
00:45
44
0.649216
0.383587
0.893248
00:45
45
0.655838
0.309745
0.908026
00:46
46
0.651342
0.311492
0.914904
00:45
47
0.633420
0.315270
0.908790
00:46
48
0.642648
0.322603
0.907006
00:46
49
0.631018
0.303884
0.917452
00:45
50
0.628049
0.314112
0.910828
00:47
51
0.624718
0.300851
0.921019
00:47
52
0.610196
0.285160
0.922038
00:47
53
0.607032
0.293710
0.923057
00:47
54
0.602499
0.297472
0.922803
00:47
55
0.604628
0.272691
0.926115
00:47
56
0.605479
0.270249
0.928153
00:47
57
0.591205
0.262621
0.927898
00:47
58
0.591620
0.275725
0.926369
00:47
59
0.587443
0.259395
0.931465
00:46
60
0.588769
0.265805
0.929936
00:47
61
0.580848
0.259401
0.931975
00:47
62
0.582864
0.258974
0.929682
00:46
63
0.577927
0.247833
0.936051
00:46
64
0.571387
0.251924
0.937070
00:47
65
0.567092
0.246839
0.935796
00:47
66
0.569558
0.244742
0.934522
00:48
67
0.562757
0.245219
0.932484
00:48
68
0.565985
0.244261
0.934522
00:47
69
0.560473
0.246916
0.935796
00:46
70
0.563191
0.245573
0.936306
00:47
71
0.557123
0.241107
0.937070
00:46
72
0.557525
0.242384
0.934013
00:47
73
0.557234
0.241791
0.935796
00:46
74
0.557565
0.241795
0.935032
00:46
75
0.555624
0.239112
0.936815
00:47
76
0.558820
0.238714
0.936561
00:47
77
0.551564
0.239402
0.936306
00:47
78
0.546191
0.239049
0.936051
00:47
79
0.541341
0.238917
0.936561
00:46
Conclusions
In this post, we have learned about convolutional neural networks (CNNs) and how they can be used for image classification tasks. We have also learned about several techniques to improve the training stability and performance of our model, including batch normalization, residual networks (ResNet), and Mixup. By applying these techniques, we were able to achieve state-of-the-art performance on the Imagenette dataset using a ResNet-50 architecture built from scratch.
Technical Insights
ImportantKey Technical Learnings
Convolutional layers are the building blocks of CNNs, which are designed to process grid-like data such as images.
Strides and padding are techniques used to control the spatial dimensions of the output feature map.
Batch normalization is a technique used to improve the training stability and performance of deep neural networks by normalizing the activations of each layer.
Residual networks (ResNet) are a type of CNN architecture that uses skip connections to allow the gradients to flow directly through the network, bypassing one or more layers.
Mixup is a data augmentation technique that creates new training samples by mixing two random samples from the training set, which can help to improve the generalization of the model and reduce overfitting.
Footnotes
Dumoulin, V. (2016). “A guide to convolution arithmetic for deep learning”.↩︎
Smith, L. (2017). “Cyclical Learning Rates for Training Neural Networks”.↩︎
Smith, L. (2017). “A Disciplined Approach to Neural Network Hyper-Parameters: Part 1 LEARNING RATE, BATCH SIZE, MOMENTUM, AND WEIGHT DECAY .↩︎
Sergey, Ioffe. (2015). “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.↩︎
He, K., Zhang, X., Ren, S., & Sun, J. (2015). “Deep Residual Learning for Image Recognition”.↩︎
He, K., Girshick, R., Dollár, P., & He, K. (2019). “Bags of Tricks for Image Classification with Convolutional Neural Networks”.↩︎