Image Classification with FastAI
Second in a series on understanding FastAI.




Objectives
So far, from Part 1, we understood how to create and deploy a model. I practice, to make your model really works, there are a lots of details that we have to check including:
- different types of layers
- regularization methods
- optimizers
- how to put layers into architectures.
- labelling techniques and much more
In this post, we will enlighten them on.
from fastai.vision.all import *
path=untar_data(URLs.PETS)
path.ls()
(path/"images").ls()
In order to extract information from strings of dataset, we can use regular expression (regex). A regular expression (link) is a special string, written in regular expression language and specifies a general rule for deciding whether another string passes a test. As the example given below, we will take a file name from scratch and then we use regex to grap all the parts of regular expression that have parentheses around them.
fname=(path/"images").ls()[1]
re.findall(r'(.+)_\d+.jpg$',fname.name)
In the next part, we will give an example of using regex to label the whole dataset by RegexLabeller.
get_y will take RegexLabellerfunction and changes it to a function which will be passed the 'name' attribute.
Then, 2 last lines resize and aug_transforms() do image augmentation.
pets = DataBlock(blocks=(ImageBlock,CategoryBlock), # independant and dependant variable
get_items=get_image_files,
splitter=RandomSplitter(seed=42),
get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'),'name'),
item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224,min_scale=0.75))
dls=pets.dataloaders(path/"images")
Presizing will grap a square randomly in the original picture. Then the second step of aug_transform will grap a random warped crop (possibly rotated) and will turn that into a square.
Because these steps will change the images (lower quality) since it requires an interpolation after each step, so FastAI (Resize()) will coordinate the image transformation in a non lossy way. And only once at the end, we will do the interpolation.

learn=cnn_learner(dls,resnet34,metrics=error_rate)
learn.fine_tune(2)
Cross-entropy loss is really much the same as MNIST loss we have defined before but it provides at least 2 benefits:
- It works even when our dependant variable has more than 2 categories
- Faster and more reliable training.
The purpose of the Cross-Entropy loss is to take the output probabilities and measure the distance from the truth table. By means of model training, we will minimize the Cross-Entropy loss.
x,y=dls.one_batch()
y
dls.vocab
Then, we can show the predictions (the activation results of final layer of our neural network) of one mini-batch
preds,_ = learn.get_preds(dl=[(x,y)])
preds[0]
The results return 37 probabilities between 0 and 1, which add up to 1 in total. To transform the activation of our model into predictions like this, we used soft-max activation function
Soft-max activation function is an extension of Sigmoid function to handle more than 2 categories. So we can obtain multi activations for multi label categories. The output of each final layer shows the likelyhood of the input item being a particular category.
As indicated in the example below, the unnormalized outputs of the neural network will be converted into probability by using Softmax fucntion. It measures how likely in terms of probability an input item belongs to a particular category.
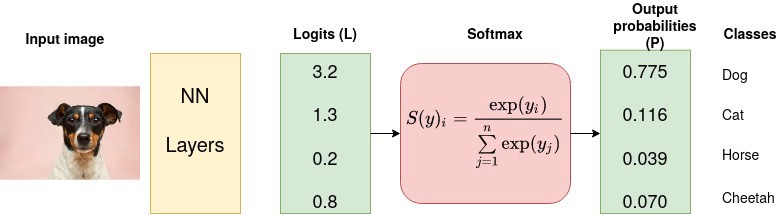
def softmax(x): return exp(x) / exp(x).sum(dim=1,keepdim=True)
When we apply Sigmoid activation function for each individual final layer, we can not guarantee that the sum of those outputs will be added up to 1. That's the reason for why we apply Softmax where it calculates the exponential of each outcome to the sum of exponential of all possible outcomes.
acts=torch.randn((6,2))*2
sm_acts=torch.softmax(acts,dim=1)
sm_acts
Because the exponential function grows very fast, so softmax activation function really want to pick one class among the others, so it will be ideal for training a classifier when we have various categories.
Entropy
The concept of entropy was proposed by Shannon in the field of information theory. By definition, Entropy of a random variable X measures the level of uncertainty ingerent in the variables possible outcomes.
For p(x) - probability distribution and a random variable X, entropy H(x) is defined as follows:
The negative sign is used to deal with the logarithm of a value in range between 0 and 1. Thus, the greater value of entropy H(x) (events have comparable probabilities), the greater of uncertainty for probability distribution and vice versa.
In the context of Machine Learning, the comparison between predicted distribution and true distribution provides us the information about the differences between those. The larger gap between those distributions, the more uncertainty of our model will be. That is what the cross-entropy loss determine:
$$ L_{CE} = - \sum _{i=1} ^{n} t_i * \log {p_i}, \quad \text{for n classes} $$where $t_i$ is the truth label and $p_i$ is the Softmax probability of the $i^{th}$ class.
In Pytorch, cross-entropy loss are available in either class instance or function instance. By default, Pytorch loss function takes the mean of the loss of all categories, so we can use reduction='none' to explicitly show the individual loss.
targ = tensor([0,1,0,0,1,1])
loss_func = nn.CrossEntropyLoss()
loss_func(acts,targ)
targ = tensor([0,1,0,0,1,1])
F.cross_entropy(acts,targ)
nn.CrossEntropyLoss(reduction='none')(acts,targ)
In order for human to understand the optimization process, we can use confusion matrix to see where our model is doing well and where its doing badly
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix(figsize=(12,12),dpi=60)

To have a cleaner view of what is going on, we can choose to show the cells of confusion matrix with the most incorrect predictions.
interp.most_confused(min_val=5)
The learning rate finder
One of the most critical part in training a model os to find a good learning rate. If the predefined learning rate is too small, it will takes many epochs to train our model and it might result in time consuming and overfitting exposure. IF it is set too high, the detrimental effects of error rate increasing might be seen.
learn = cnn_learner(dls,resnet34,metrics=error_rate)
learn.fine_tune(1,base_lr=0.2)
In 2015, resercher Leslie Smith came up with a brilliant idea of learning rate finder link. His idea starts with a very small learning rate and examine the loss over one mini-batch. Then, he increase learning rate by a certain percentage and keep doing that until the loss get worse. That the point we know that we have over-reacted and we should choose a learning rate lower than this point.
lr_min,lr_steep = learn.lr_find()

learn = cnn_learner(dls,resnet34,metrics=error_rate)
learn.fine_tune(2,base_lr=0.008)
Transfer learning will take a set of parameters that have been previously trained and throw away the last layer of pretrained model. Then we replace by a layer with random weights and we train that.
The next task is to fine tune the newly added weight to align with our new objective. fine_tun is a method we called to operate that. It does 2 things:
- train the randomly added layers for one epoch with all other layer frozen
- unfreeze all of the layers and train them all for the number of epoch requested.
learn.fine_tune??
There are several parameters in fine_tune we shoud notice:
- self.freeze(): make only the last layer's weight get step and freeze the other layers.
- self.fit_one_cycle() : update the newly added weights in one cycle, it trains model without using fine_tune. In summary, it starts training at a lower learning rate, gradually increase ot for the first section of training and then gradually decrease it again for the last section of training.
learn = cnn_learner(dls,resnet34,metrics=error_rate)
learn.fit_one_cycle(3,3e-3)
learn.unfreeze()
learn.lr_find()

learn.fit_one_cycle(6,lr_max=1e-5)
Intuitively speaking, in transfer learning, the deepest layers (beginning layers) of our pretrained model might not need as high a learning rate as the last ones, so we should probably use different learning rate approach for different layers. That what FastAI called discriminative learning rate .
The idea behind this is simple: we apply lower learning rate for the early layers of the neural network and higher learning rate for the later ones.
In FastAI, we will pass a Python slice object anywhere that a learning rate is expected. The first value of slice is the learning rate of the starting layer and the last value of the slice is the final layer. The layers in between share the multiplicatively equidistant learning rate throughout the slice.
learn = cnn_learner(dls,resnet34,metrics=error_rate)
learn.fit_one_cycle(3,3e-3)
learn.unfreeze()
learn.fit_one_cycle(12,lr_max=slice(1e-6,1e-4))
It literally increase the numbers of layers of our architecture (more activation functions, linear model). For instance, resnet architecture comes with 18,34,50,101,152 layer variants, pretrained with ImageNet. A larger version of the resnet returns a better training loss, but it can suffer more from overfitting.
In additions, the bigger model and larger batch-size is, the memory requirement for GPU is higher.
Another downside of training data with deeper architecture is time consuming, as it will take more time to train a larger model.µ
So, in this part, we have learned some important practical tips:
- Preparing data for modelling (presizing)
- Fitting the model (learning rate finder, unfreezing, fine_tune, discriminative learning rate, epochs, deeper architecture)
- Entropy loss discusison